mapreduce and block processing
We're going to be frank with you: we didn't write a serial version of the MapReduce code that traces the path back to philosophy. We've only got two computers between us, and I promise you that grad school students can't be computerless for the many hours necessary to run that code. Not touching my laptop for the seven hours our MapReduce code was running was hard enough.
I can, however, show you speed-ups for other parts of the code, using MPI:
I can, however, show you speed-ups for other parts of the code, using MPI:
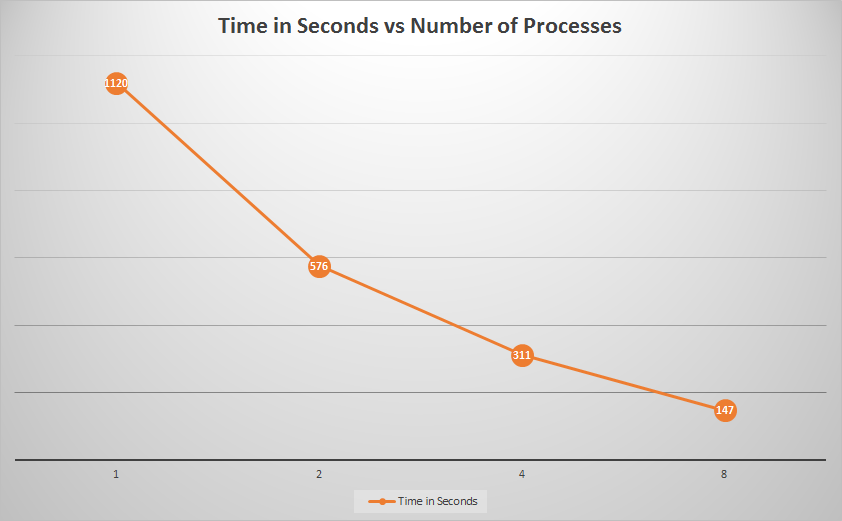
Here we can see the amount of time needed to parse the links from a subset of the Wikipedia page blocks. (These were our times running on only 11 blocks.) As we can see, there is a tremendous speedup from one to eight processes... nearly eight times! This is to be expected, since the code is embarrassingly parallel.
MPI: infinite Loop finder
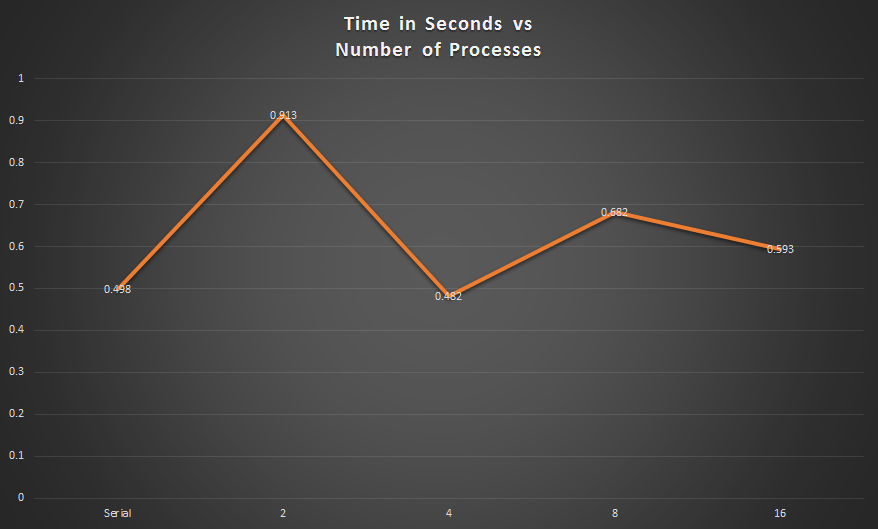
Here we can see the amount of time needed to trace the paths of links with infinite loops on a subset of the data. Interestingly, time didn't strongly correlate with number of processes.
We'd like to take a moment to comment of this lack of correlation in the graph directly above. Originally, we were simply iterating through the link list until an article appeared in the dictionary twice. To speed up implementation, we implemented dictionary of paths that have already been traced. Then, if a given path hits a link whose path is already known, the process should stop tracing the path back and instead simply copy in the known path. This quick trick shaved a few seconds off our serial run time.
However, in MPI, processes share their dictionary with one another after they've updated their own 10 times. However, using an implementation like this, the order of the input data matters hugely, as processes can save a large amount of time if they happen to trace paths for partial paths that are already in their respective dictionaries (before sharing). We've concluded this with a reasonable degree of certainty after testing it empirically (by changing the order of the lines in the input file). The graph of time above highlights this principle: though for four processes, each process will have to compute more than it would have to with 16 processes, the order of the output is preferable, such that the each process can find a relatively large percentage of partial paths in its dictionary.
However, as we can see, it seems that implementing the parallel code shows no advantage for this part of the process.
THREAD POOLS
We also had some fun and experimented with thread pools. Our original script that processed/parsed the Wikipedia blocks of articles was very serial and processed one block at a time. We could have used MPI (a script is written for it) to split up the blocks and have them run in parallel. However, that means transfers of large amounts of data, one being transferring that data to our SEAS folder so that we could run the MPI. After many attempts, we realized it was a hassle to put 12+ GB of data onto VirtualBox, but the serial script was taking upwards of 7-12 hours to run. We thus decided to write a script that utilized thread pooling, here. This script, when you run it on your computer, will take up all of your computer's processors. We will not go into detail here, but in short, we created a pool, and essentially mapped our blocks to the processes in each pool. We utilized multiprocessing, a python package that supports spawning processes using an API similar to the threading module. The module allowed us to fully leverage multiple processors on our machine. This gave us a 10x speedup, finishing in approximately 40 minutes.
However, in MPI, processes share their dictionary with one another after they've updated their own 10 times. However, using an implementation like this, the order of the input data matters hugely, as processes can save a large amount of time if they happen to trace paths for partial paths that are already in their respective dictionaries (before sharing). We've concluded this with a reasonable degree of certainty after testing it empirically (by changing the order of the lines in the input file). The graph of time above highlights this principle: though for four processes, each process will have to compute more than it would have to with 16 processes, the order of the output is preferable, such that the each process can find a relatively large percentage of partial paths in its dictionary.
However, as we can see, it seems that implementing the parallel code shows no advantage for this part of the process.
THREAD POOLS
We also had some fun and experimented with thread pools. Our original script that processed/parsed the Wikipedia blocks of articles was very serial and processed one block at a time. We could have used MPI (a script is written for it) to split up the blocks and have them run in parallel. However, that means transfers of large amounts of data, one being transferring that data to our SEAS folder so that we could run the MPI. After many attempts, we realized it was a hassle to put 12+ GB of data onto VirtualBox, but the serial script was taking upwards of 7-12 hours to run. We thus decided to write a script that utilized thread pooling, here. This script, when you run it on your computer, will take up all of your computer's processors. We will not go into detail here, but in short, we created a pool, and essentially mapped our blocks to the processes in each pool. We utilized multiprocessing, a python package that supports spawning processes using an API similar to the threading module. The module allowed us to fully leverage multiple processors on our machine. This gave us a 10x speedup, finishing in approximately 40 minutes.
